
[paper] MQSim
- FAST'18
- Onur Mutlu, ETH Zürich, CMU
1. Motivation
- 之前的模拟器没有对新协议(NVMe)的关键特性进行正确建模
- 之前的模拟器不能快速达到稳态
- 之前的模拟器都不支持 end-to-end latency
2. Challenges
2.1 Multi-Queue Support
Modern Multi-Queue SSD 和 传统的 SSD 的区别在于它使用 Multi-Queue, 直接将 Application 的请求提交到 SSD, 而不需要经过 OS Scheduler (原本是 OS Scheduler 保证公平性)
这样实现的 Modern Multi-Queue SSD 就需要自己控制调度的公平性, 然后做了一堆实验说明了这个公平性是怎么样
2.2 Steady-State Behavior
SSD performance evaluation standards 提到测试性能需要在 steady-state, 所以 preconditioning (预处理) 是必要的 3 个原因:
- GC 会影响 SSD 性能, 但是全新的 SSD 不会 GC
- 减少 Cache 的影响, 比如 write cache, cache 满了会影响写的写的性能, 或者说没有cache才是真实的性能
- physical data placement 主要由运行的历史决定(之前的程序是如何写如何读, 决定了现在的 physical data placement). 比如, 哪些 page 是空闲的, 取决之前的 request 如何写入如何让 page invalid, 在稳态下, channel/chip 的并行性会受到影响
2.3 Real End-to-End Latency
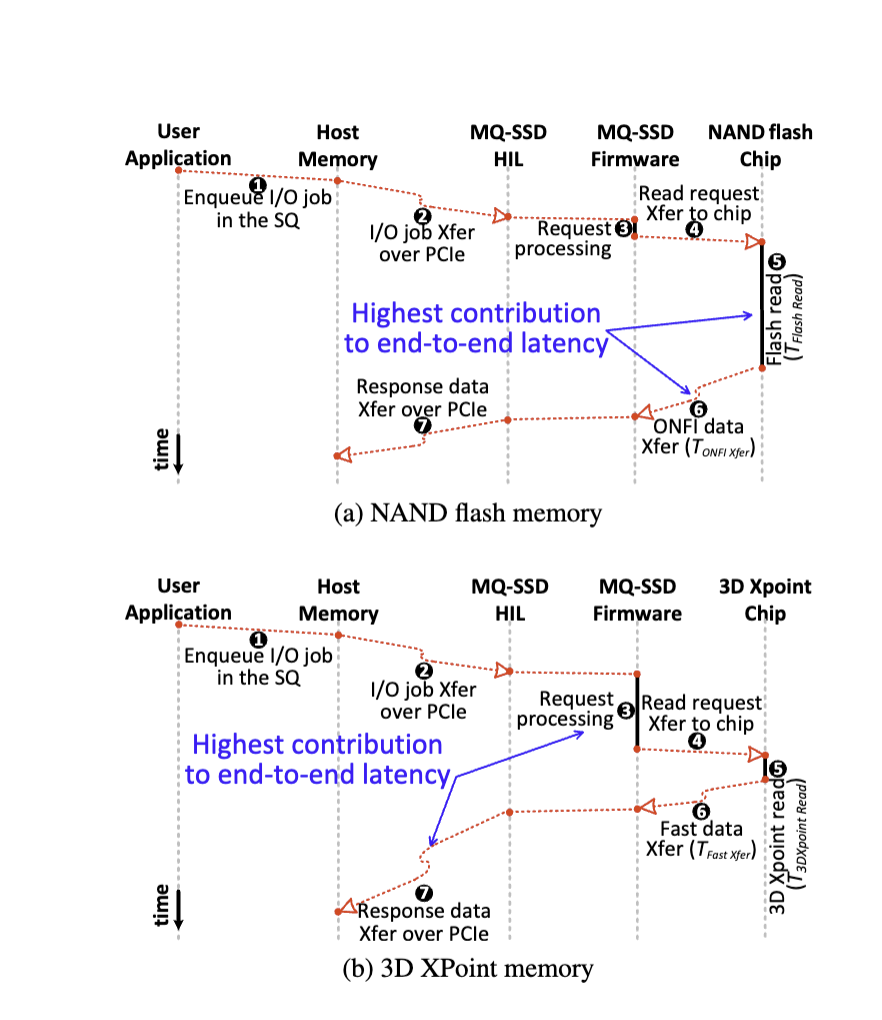
end-to-edn latency 主要组成部分如下图所示, 传统的 NAND 在 I/O bus 上的花的时间并不多
而现在出现的 3D XPoint memory, I/O bus 的时间比 flash chip 上花的时间要多, 导致只 evaluate SSD 内部的时间是不合理的, 如下图, 可以看到 3D XPoint memory 在 chip 上花的时间是很少的, 相较之下 I/O 时间就会变多 (OSDI’ 22 best paper XRP 用 eBFP 就和这个有一定关系, 减少了 system call的时间)
3. Design
总体架构图
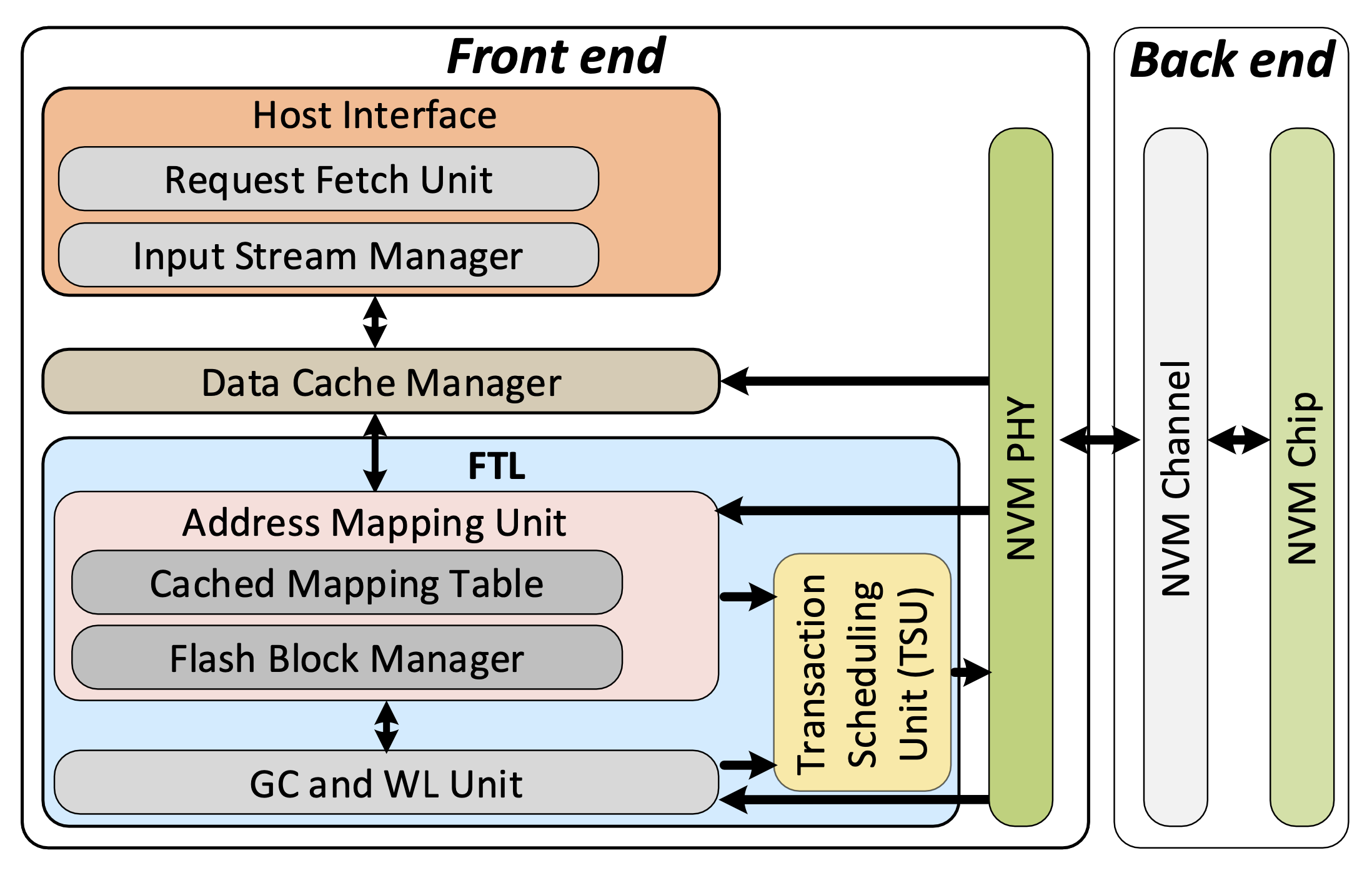
3.1 Back End Model
3.1.1 latency
3 major latency components of the SSD back end
- address 和 command 传输时间
- flash memory read/write/erase… 执行的时间, 称作 tR/tPROG/tERASE…
- data transfer to/from memory chips 的时间
(一般来说, 1. 3. 合起来被称为 tDMA)
3.1.2 parallism
MQSim’s flash model considers the constraints of die- and plane-level parallelism, and advanced command execution
advanced command execution 这优化似乎是为 GC 之类的服务, 如果是 copy-back, 即 read 一个区域然后 write 另一区域, 这整个操作都在 Flash memory 内部进行, 不需要与 FTL/ECC…交互
3.1.3 decouple write and read operation
有助于利用 modern falsh memeory chip large page size 的优势, 提高 write 性能, 防止对 read 性能的负面影响
- write, 大小总是 page-sized, 如果是 partially-update, 需要先读不变的部分. 假设 123是一个 page, 如果我们 update 2, 需要先读出 1 和 3, 拼成一个 page, 写入一个新的地址
+--------+-------------------+-----------------+
| 1 | 2 | 3 |
| | | |
+--------+-------------------+-----------------+
- read, 支持 partial read, 支持小于 page size 读, 减少了 tDMA. 还是用上面这个例子, user 只需要 2 这个部分的 data, MQSim 可以只"读"这一部分, 只 transfer 这一部分
3.2 Front End Model
3.2.1 Host-Interface Model
用于和 host 交互, 类似与 NVMe 中 doorbell, sq, cq 之类的内容
- 支持 NVMe/SATA 的 command queue, 支持修改
QueueFetchSize - 支持 NVMe 协议中不同的优先级的 host-side request queues
3.2.2 Data Cache Manager
就是存 Data 的, PCIe 4.0 的有缓盘, 有缓指的就是这个 cache, 现在主流的配置一般在 2G 左右.
- DRAM-based cache with LRU replacement policy, 3 modes, recently-written/recently-read/both
- 考虑了 DRAM access 的竞争和延迟
3.2.3 FTL Components
3 个主要的组件
- 地址翻译单元(address translation unit): SOTA 地址翻译策略
- 垃圾回收和磨写均衡
- GC candidate block selection algorithms
- GC and flash management mechanisms including preemptible GC I/O scheduling, intra-plane data movement, …
- 事务调度单元(transaction scheduling unit): SOTA transaction scheduling schemes
- 都支持 multi-flow
3.3 Modeling End-to-End Latency
- Variable Latencies (可变的延迟)
- the time required to read/write from/to the data cache, 因为这个可能会有 contention
- the time to fetch mapping data from flash storage in case of a miss in the cached address mapping table, 当 FTL 中查不到当前的 logical page address 的映射的话, 就会首先读一次 mapping table
- Constant Latencies.
- Transfer time, 与 HOST 交互之间的 I/O (NVMe sq cq), user data
- FTL 执行时间…
3.4 Modeling Steady-State Behavior
- 什么时候执行?
在执行真正的 simulation 之前进行 precondition
- 如何执行?
- 所有 physical page 要被确定是 valid 还是 invalid. 分析 trace 中 I/O LPA 的特征, 结合 steady-state valid/invalid page distribution, 确定 page 的状态(invalid/valid). 简单来说就是改变每个 block 读写状态,
- trace 的特征也可以用来 warm up write cache
从代码来看, 其实也会 warm up FTL
4. 总结
- 第一个支持 NVMe/Multi-Queue 的 SSD Simulator
- 支持 precondition, 可以快速到达稳态
- 支持 end-to-end latency