
[Notes] An Introduction to the Linux Kernel Block IO Stack
主要是三个部分:
- What is a Block Device ? (什么是 块设备)
- Anatomy of a Block Device (块设备剖析)
- I/O Flow in the Block Layer
What is a Block Device ?
Definition
是 hardware abstraction, 表示 data 以固定大小存储(e.g. 512/2048/4096 bytes)和访问 的 hardware
和 Character Devices 不同, 在 block device 的 blocks 可以随机访问, 前者只能顺序访问
一般来说, block device 表示的 persistent mass storage hardware, 但是也不全是, 比如 RAM Disk.
What is a “Block” anyway
一个 block 是指用来和 block device(或者与之相关的 hardware) 通讯(communication)固定大小的 bytes, 可以理解为最小的单位. 并且在不同的 software stack 定义不同
- Usersapce Software: application 定义, 一般指通过一个 syscall read/write 的 data 多少
- VFS: Linux 中文件系统 I/O 的最小单位, 512 ~ PAGESIZE bytes
- Hardware: 也可以称作 sector (笔者延伸: 比如在 NVMe 协议中 logical block address, 这里的 block 指的是 sector, 而非 SSD 中的 block)
- Logical: smallest unit in bytes that is addressable on the device.
- Physical: smallest unit in bytes that the device can operate on without resorting to read-modify-write.
- Physical may be bigger than Logical block size
Using Block Devices in Linux (Examples)
列举出所有可用的 block devices
ls /sys/class/block
nvme0n1 nvme0n1p1 nvme0n1p2 nvme0n1p3 nvme0n1p4 nvme1n1 nvme1n1p1 nvme1n1p2 nvme1n1p3 nvme1n1p4 sda sda1
# 这里的 nvme<x>n<y>p<z>, x 指的是 nvme 编号, y 指的是 namespace, z 指的是 partition, (其实这里是我猜的, 也许是对的)
(笔者补充, 这些都是指向 /sys/devices 文件夹的 symbolic links)
ls /sys/class/block -al took 16ms 20:50:35
total 0
drwxr-xr-x 2 root root 0 Mar 21 20:50 .
drwxr-xr-x 72 root root 0 Mar 22 2025 ..
lrwxrwxrwx 1 root root 0 Mar 22 2025 nvme0n1 -> ../../devices/pci0000:00/0000:00:02.2/0000:0e:00.0/nvme/nvme0/nvme0n1
lrwxrwxrwx 1 root root 0 Mar 22 2025 nvme0n1p1 -> ../../devices/pci0000:00/0000:00:02.2/0000:0e:00.0/nvme/nvme0/nvme0n1/nvme0n1p1
lrwxrwxrwx 1 root root 0 Mar 22 2025 nvme0n1p2 -> ../../devices/pci0000:00/0000:00:02.2/0000:0e:00.0/nvme/nvme0/nvme0n1/nvme0n1p2
lrwxrwxrwx 1 root root 0 Mar 22 2025 nvme0n1p3 -> ../../devices/pci0000:00/0000:00:02.2/0000:0e:00.0/nvme/nvme0/nvme0n1/nvme0n1p3
lrwxrwxrwx 1 root root 0 Mar 22 2025 nvme0n1p4 -> ../../devices/pci0000:00/0000:00:02.2/0000:0e:00.0/nvme/nvme0/nvme0n1/nvme0n1p4
lrwxrwxrwx 1 root root 0 Mar 22 2025 nvme1n1 -> ../../devices/pci0000:00/0000:00:01.2/0000:02:00.0/nvme/nvme1/nvme1n1
lrwxrwxrwx 1 root root 0 Mar 22 2025 nvme1n1p1 -> ../../devices/pci0000:00/0000:00:01.2/0000:02:00.0/nvme/nvme1/nvme1n1/nvme1n1p1
lrwxrwxrwx 1 root root 0 Mar 22 2025 nvme1n1p2 -> ../../devices/pci0000:00/0000:00:01.2/0000:02:00.0/nvme/nvme1/nvme1n1/nvme1n1p2
lrwxrwxrwx 1 root root 0 Mar 22 2025 nvme1n1p3 -> ../../devices/pci0000:00/0000:00:01.2/0000:02:00.0/nvme/nvme1/nvme1n1/nvme1n1p3
lrwxrwxrwx 1 root root 0 Mar 22 2025 nvme1n1p4 -> ../../devices/pci0000:00/0000:00:01.2/0000:02:00.0/nvme/nvme1/nvme1n1/nvme1n1p4
lrwxrwxrwx 1 root root 0 Mar 22 2025 sda -> ../../devices/pci0000:00/0000:00:02.1/0000:03:00.0/0000:04:0d.0/0000:0d:00.0/ata4/host3/target3:0:0/3:0:0:0/block/sda
lrwxrwxrwx 1 root root 0 Mar 22 2025 sda1 -> ../../devices/pci0000:00/0000:00:02.1/0000:03:00.0/0000:04:0d.0/0000:0d:00.0/ata4/host3/target3:0:0/3:0:0:0/block/sda/sda1
读取 block device
dd if=/dev/<...> of=/dev/null bs=2MiB
# 这里就不演示了, 如果是 nvme 设备, 也可以用 nvme-cli
Listing the topology of a stacked block devices:
lsblk −s /dev/mapper/rhel_t3545003−root # 我没有这玩意, 抄的 slides
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
rhel_t3545003−root 253:11 0 9G 0 lvm /
+−mpathf2 253:8 0 9G 0 part
+−mpathf 253:5 0 10G 0 mpath
+−sdf 8:80 0 10G 0 disk
+−sdam 66:96 0 10G 0 disk
Some More Examples for Block Devices
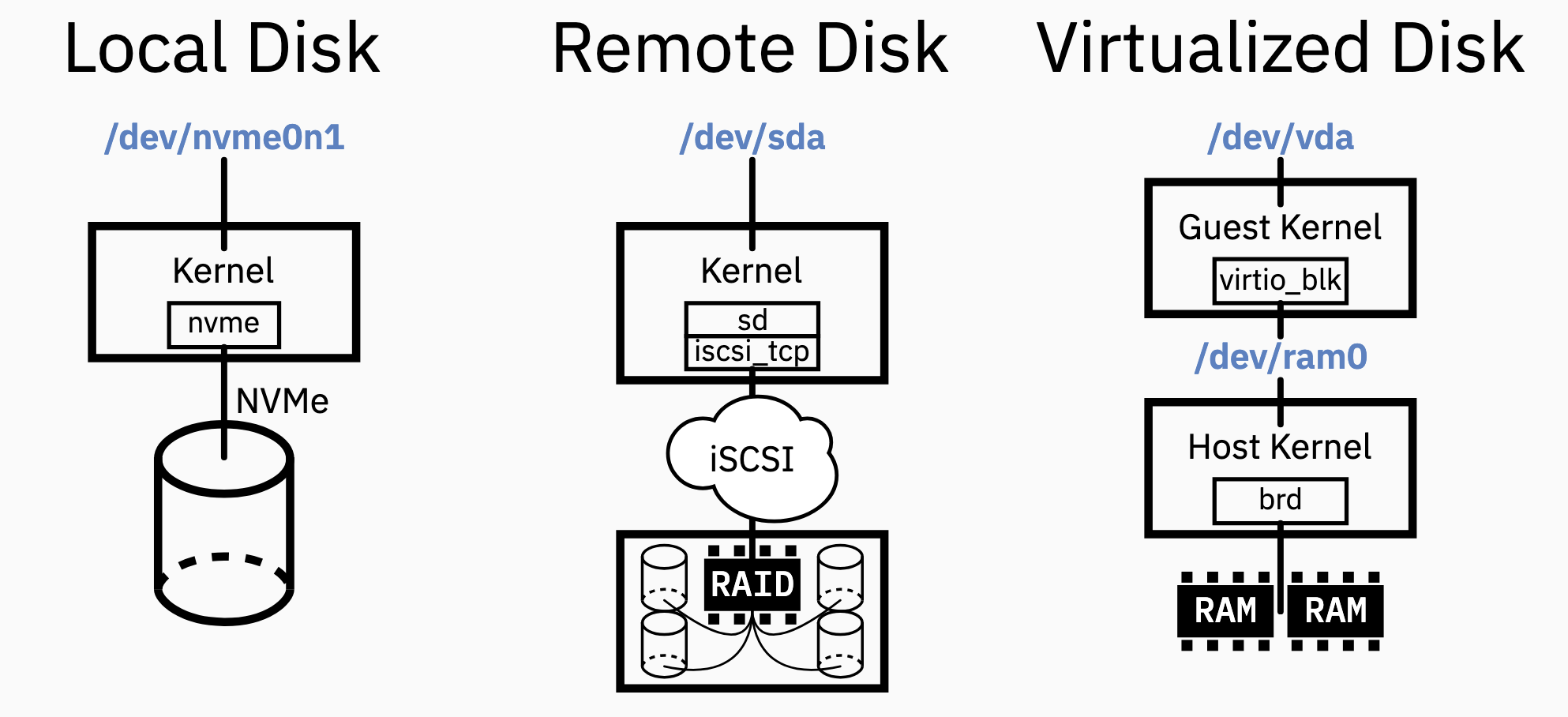 Examples for block device setup with different hardware backends
Examples for block device setup with different hardware backends
Anatomy of a Block Device
Structure of a Block Device: User Facing
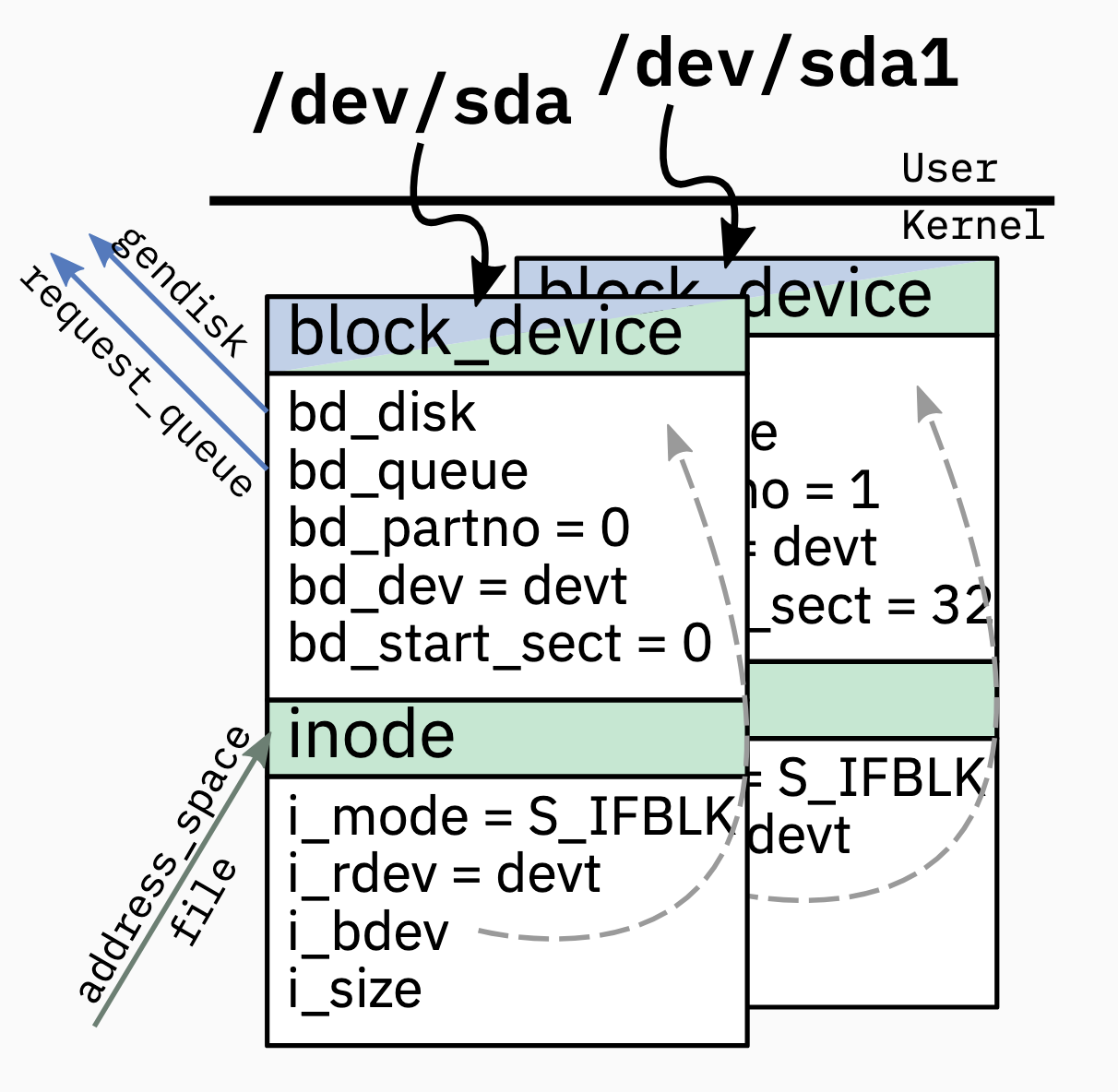
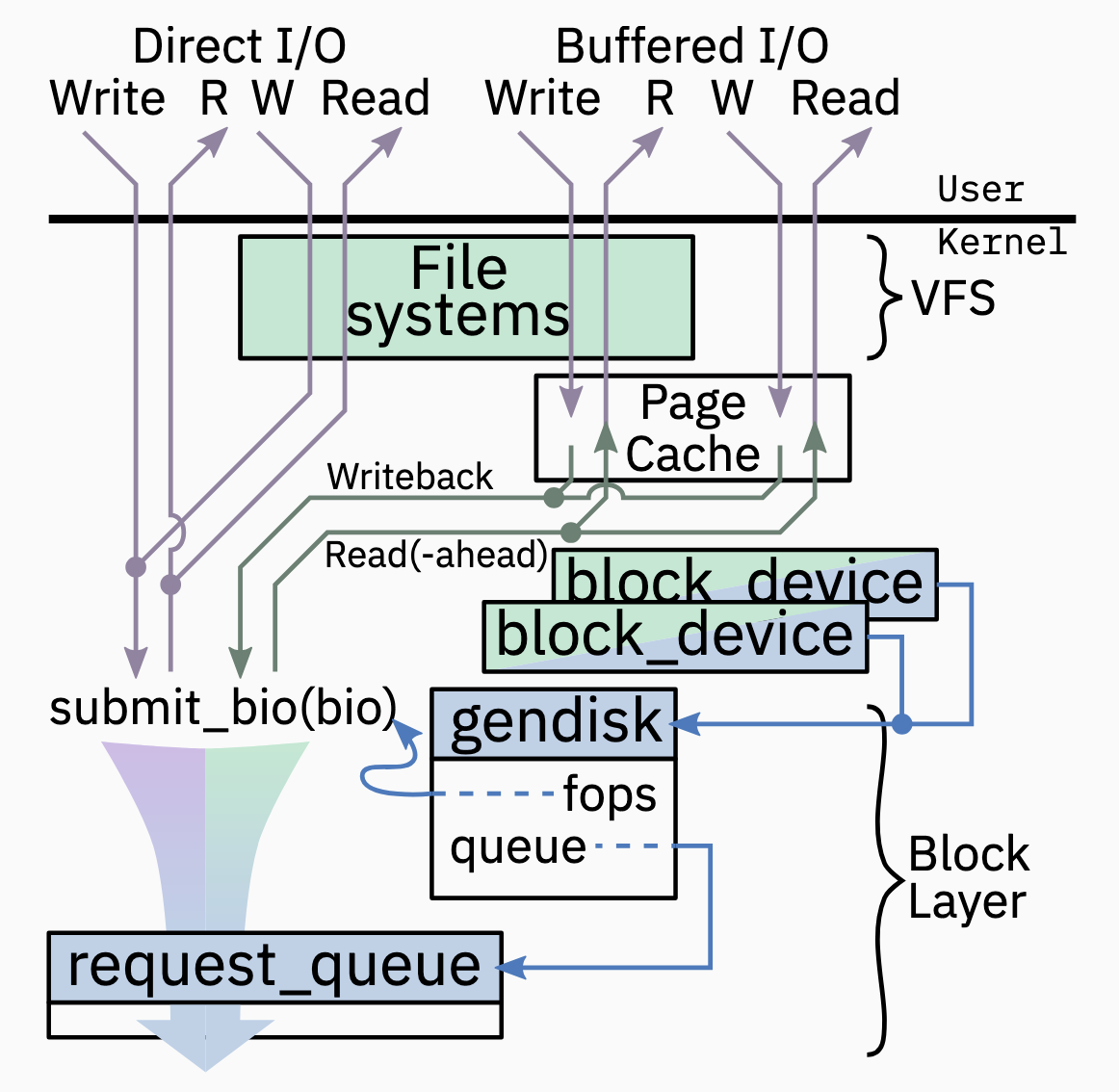
block_device. Userspace interface; 表示一个在/dev的特殊文件, and links to other kernel objects for the block device; partitions point to same disk(gendisk) and queue (request_queue) as whole device. 如下图,/dev中有两个类似文件,/dev/sda和/dev/sda1, 各表示一个block_device, 但是拥有不同的bd_partno和bd_start_sect, 一般情况下, 使用fdisk对/dev/sda进行分区, 之后就会产生一个/dev/sda1inode. 每个 block device 都有一个 inode, 这 inode 可以被 VFS 使用 (笔者注, 在 5.15 似乎没有 i_bdev 这个 field, 需要通过
inode->i_sb->s_bdev拿到)fileandaddress_space. 用户态的进程 open 特殊文件 (/dev/**); in kernel represented asfilewith assignedaddress_spacethat point to block device incode.
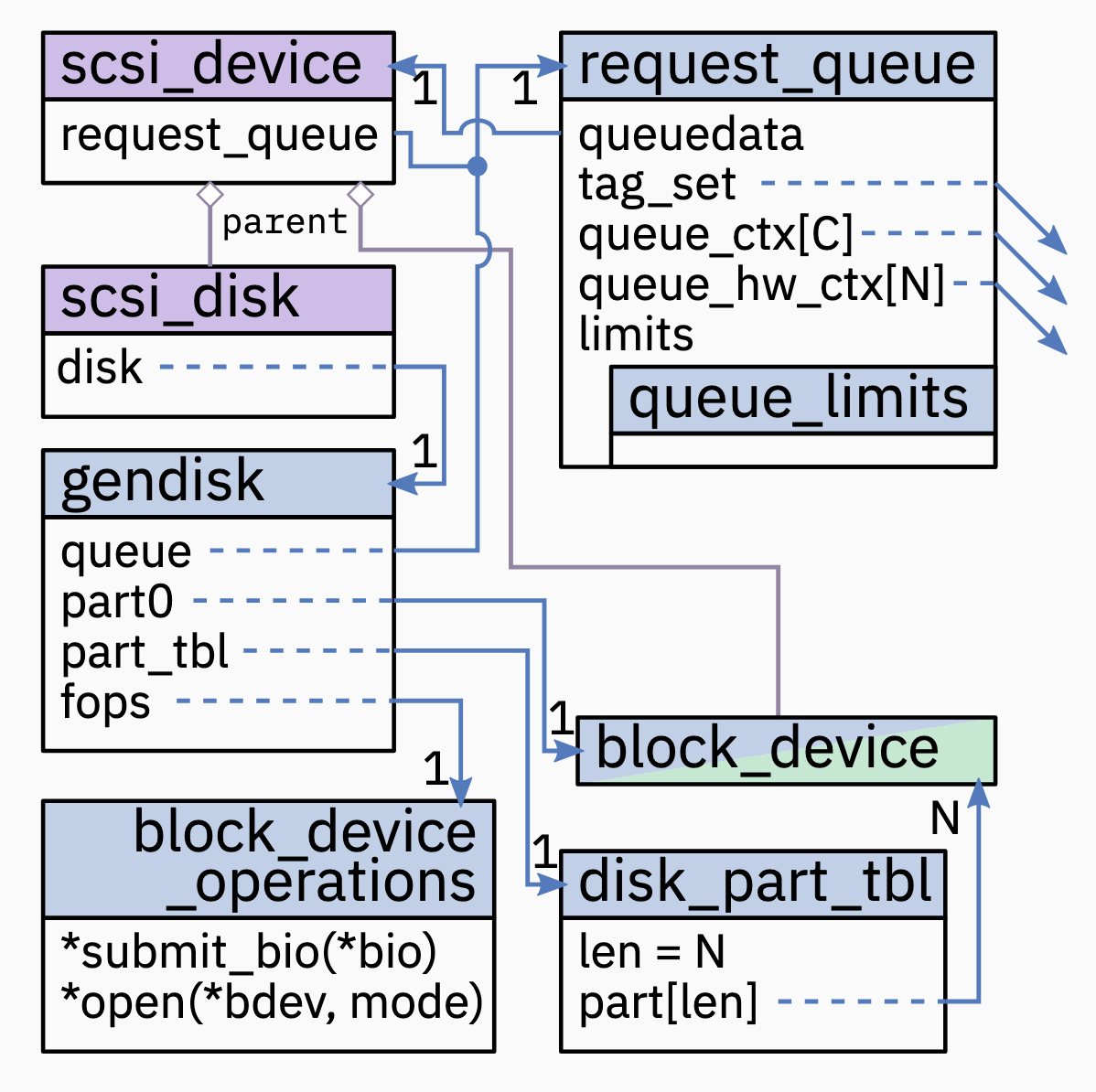
Structure of a Block Device: Hardware Facing
gendisk和request_queue. 任何 block device 的主要部分; abstract hardware detials for higher layers;gendisk表示整个可寻址的空间(addressable space);request_queue表示如何请求服务.disk_part_tbl(5.15 也许是struct xarry part_tbl) points to partitions – represented asblock_device– backed bygendiskscsi_deviceandscsi_disk设备驱动; 为所有 SCSI-like hardware (incl. Serial ATA, SAS iSCSI, FCP,…) 提供 common/mid layer
Queue Limits (Queue 限制)
// 5.15
struct queue_limits {
enum blk_bounce bounce;
unsigned long seg_boundary_mask;
unsigned long virt_boundary_mask;
unsigned int max_hw_sectors; // Amount of sectors(512 bytes) that a device can handle per request.
unsigned int max_dev_sectors;
unsigned int chunk_sectors;
unsigned int max_sectors; // Softlimit used by VFS for buffered I/O (can be changed).
unsigned int max_segment_size; // Maximum size a segment in a request's scatter/gather list can have.
unsigned int physical_block_size; // Smallest unit in bytes handled without read-modify-write.
unsigned int logical_block_size; // Smallest possible unit in bytes taht is *addressable* in a request.
unsigned int alignment_offset;
unsigned int io_min;
unsigned int io_opt; // Perferred size in bytes for requests to the device.
unsigned int max_discard_sectors;
unsigned int max_hw_discard_sectors;
unsigned int max_write_same_sectors;
unsigned int max_write_zeroes_sectors;
unsigned int max_zone_append_sectors;
unsigned int discard_granularity;
unsigned int discard_alignment;
unsigned int zone_write_granularity;
unsigned short max_segments; // Maximum amount of scatter/gather elements in a request.
unsigned short max_integrity_segments;
unsigned short max_discard_segments;
unsigned char misaligned;
unsigned char discard_misaligned;
unsigned char raid_partial_stripes_expensive;
enum blk_zoned_model zoned;
};
- Attached to the Request Queue structure of a Block device
- hardware 的抽象, firmware 和 设备驱动的属性, 这个属性影响了 request 是如何被放置的 (layout out)
- 对于 stacked block devices 非常重要
- 比如, 见上面代码的注释
Multi-Queue Request Queues
以前, Linux 中的 request queue 是单线程工作的, 并且没有将 requests 和特定的处理器关联. 所以无法充分利用多核系统和拥有多个 queue (e.g. NVMe) 新型存储系统; 大量缓存抖动 (cache thrashing) (比如, CPU 0 生成了一个 request, 如果 migrate 到 CPU 5, 就会发生 cache thrashing)
真正支持 Multi-Queue(MQ) 在 Linux 3.13: blk-mq
- I/O requests are sheduled on a hardware queue assigned to the I/O generating processor; responses are meant to be received on the same processor.
- 每个处理器各自保留必要的 I/O submission 和 response-handling 的 structure ; 尽量不共享状态.
- old single threaded queue 在 Linux 5.0 被移除
Block MQ Tag Set: Hardware Resource Allocation
首先先介绍一下 什么是 tag ? Tag-based completion
In order to indicate which request has been completed, every request is identified by an integer, ranging from 0 to the dispatch queue size. This tag is generated by the block layer and later reused by the device driver, removing the need to create a redundant identifier. When a request is completed in the driver, the tag is sent back to the block layer to notify it of the finalization. This removes the need to do a linear search to find out which IO has been completed.
以上是 Linux Kernel Docs 提到的 Tag-based completion, 可以简单理解为 tag 就是一个 index, 用来给 request 标号, 使得可以快速定位哪个 request 已经完成.
以下来自伟大的 ChatGPT o3-mini-high, 简而言之就是一个用来分配 tag 以及其他 block layer 所需的参数 的数据结构
The “Block MQ Tag Set” is a key data structure (defined as struct blk_mq_tag_set) in the Linux kernel’s multi-queue (blk-mq) block I/O subsystem. It is used to configure and manage the pool of tags that uniquely identify I/O requests across the multiple hardware queues. In essence, it encapsulates all the parameters needed by the block layer to allocate, track, and complete requests efficiently without incurring the overhead of linear searches—crucial for achieving high IOPS on modern storage devices (like SSDs). Key points include:
- Purpose: It provides a mechanism to assign a unique identifier (tag) to each block I/O request. These tags are used by both the software staging queues (per-CPU) and the hardware dispatch queues.
- Contents: The structure contains:
- A pointer to a set of operations (blk_mq_ops) that define driver-specific behaviors.
- Mapping information between software queues and hardware queues.
- The number of hardware queues, queue depth (maximum tags per queue), and reserved tags.
- Additional configuration data (like command size, NUMA node info, timeout, flags, and driver-specific data).
- Role in blk-mq: By preallocating and managing a pool of tags, the blk-mq subsystem minimizes lock contention and allows efficient and parallel submission and completion of I/O requests on multi-core systems.
在回到这个 talk, 似乎就能理解为什么说 “Block MQ Tag Set: Hardware Resource Allocation”
- Per hardware queue resource allocation and management
- Requests (Reqs) are pre-allocated per HW queue (
blk_mq_tags) - Tags are index into the request array per queue, or per tag set (new in 5.10)
- Allocation of tags handled via special data-structure:
sbitmap - Tag set also provides mapping between CPU and hardware queue; objective is either 1:1 mapping, or cache proximity
 
(其实对于这一部分还是不是很懂)
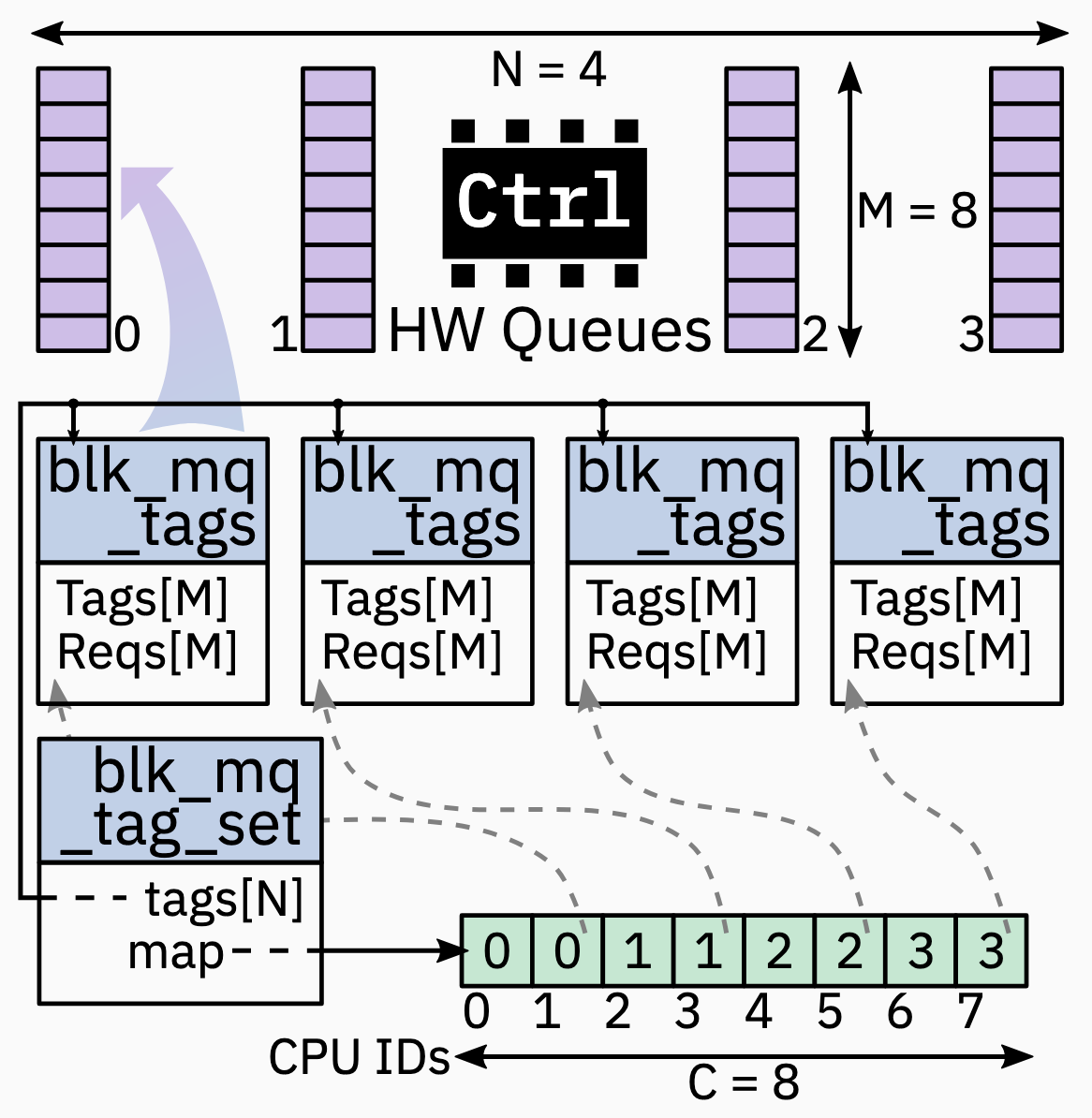
Block MQ Soft- and Hardware-Context
- Hardware context(
blk_mq_hw_ctx=hctx) 每个 hardware queue 都存在一个, 一一对应; hosts work item (kblockd work queue) scheduled on matching CPU; 从关联的 ctx (这里指代的是 software context) 拉取 requests 然后 submits 它们到 hardware - Software context (
blk_mq_ctx=ctx) 是每个 CPU 一个; 在没有 Elevator 的情况, 是简单 FIFO queues request; 根据 tag set mapping 与指定的 HCTX 关联
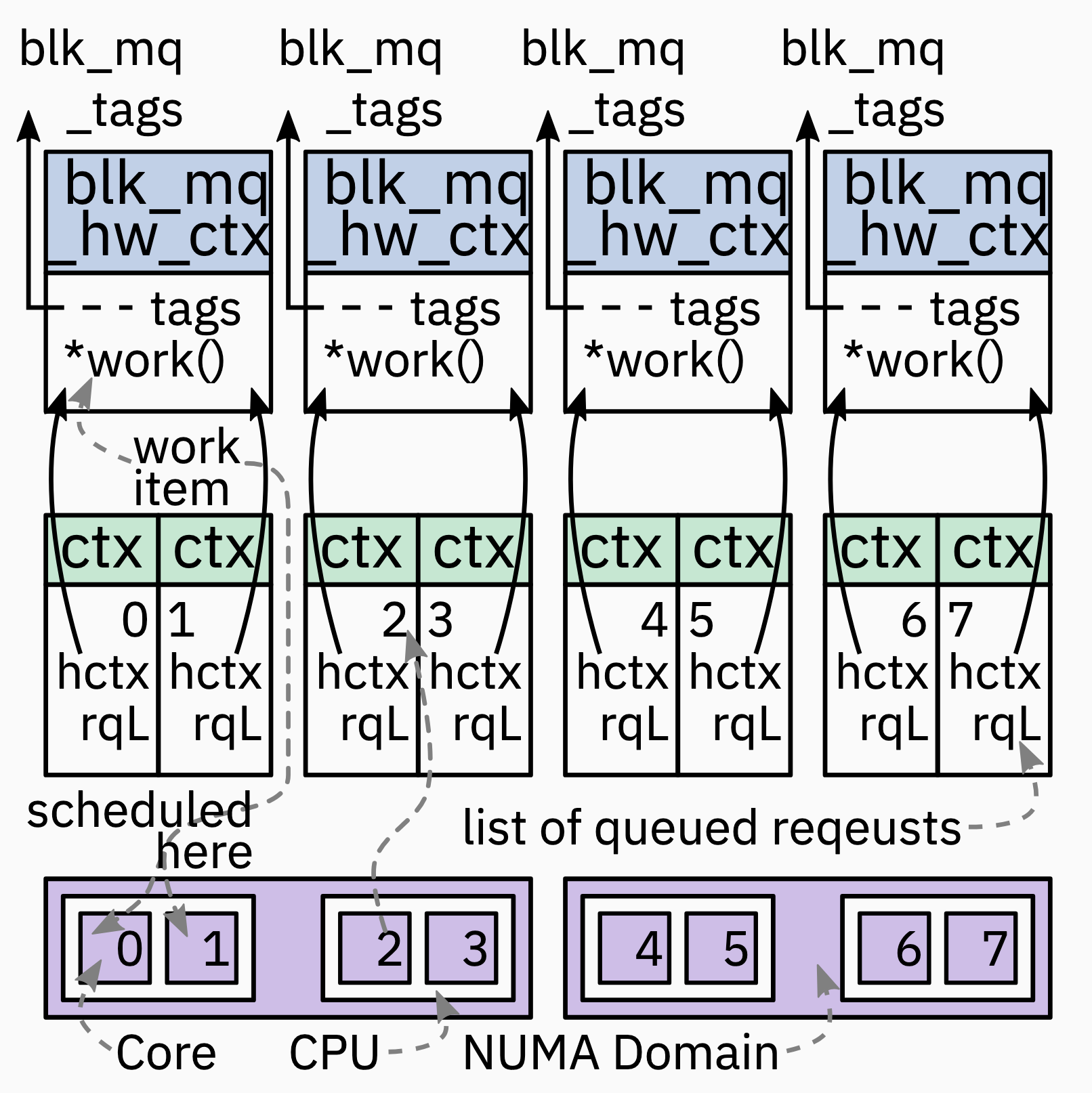
Block MQ Elevator / Scheduler
- Elevator = I/O Scheduler
- Can be set optionally per request queue
(
/sys/class/block/<name>/queue/scheduler)
$ cat /sys/class/block/nvme0n1/queue/scheduler # 这个是 NVMe 设备, 是 none
[none] mq-deadline kyber bfq
$ cat /sys/class/block/sda/queue/scheduler # 这个 SATA, 就是 mq-deadline
none [mq-deadline] kyber bfq
接下来是介绍一些调度算法, Linux Kernel Docs
- mq-deadline, based on old deadline scheduler; doesn’t handle MQ context affinities; default for device with 1 hardware queue (对于 SATA 的来说, default 是 mq-deadline, 上面的结果也可以发现); limits wait-time for requests to prevent starvation (500ms for reads, 5s for writes)
- kyber, 唯一的 MQ native scheduler; 目标是通过动态限制 queue-depth, 来保证 latency 目标 (2ms for reads, 10ms for writes)
- bfq, Only non-trivial I/O scheduler (replaces old CFG scheduler); doesn’t handle MQ context affinities; 目的主要是为了发出 I/O 的进程提供公平性
- none, Default for device with more than 1 hardware queue(比如 NVMe, 上面的结果也可以看到, NVMe 设备是 none, 原因应该是 multi-queue 的协议足够快); simply FIFO via MQ software context
这里的 MQ context affinities 应该指的是 (感谢 ChatGPT)
The MQ system tries to keep I/O requests associated with a particular CPU or context on the same queue. This helps in reducing overhead (like cache misses or lock contention) by keeping processing “local” to where the request originated
感觉 Block MQ 这部分都没咋听懂
What About Stacked Block Devices?
- Device-Mapper (dm) and Raid (md) use virtual/stacked block device on top of existing hardware-backed block devices ([15, 21])
- Examples: RAID, LVM2, Multipathing
- Same structure as shown on page 6 and 7, without hardware specific structures, stacked on other block_devices
- BIO based: doesn’t have an Elevator, an own tag-set, nor any soft-, or hardware-contexts; modify I/O (BIO) after submission and immediately pass it on
- Request based: have full set of infrastructure (only dm-multipath atm.); can queue requests; bypass lower-level queueing
queue_limitsof lower-level devices are aggregated into the “greatest common divisor”, so that requests can be scheduled on any of them- holders/slaves directories in sysfs show relationship
I/O Flow in the Block Layer
Submission of I/O Requests from Userspace (Simplified)
I/O submission 主要分为两个部分
- Buffered I/O, Requests served via Page Cache;
- Writes cached and eventually – ususally asynchronously – written to disk via Writeback
- Reads served directly if fresh, otherwise read from disk synchronously
- Direct I/O, Requests served directly by backing disk; alignment and possibly size requirements; DMA directly into/from User memory possible
For syncronous I/O system calls, tasks wait in state TASK_UNINTERRUPTIBLE
A New Asynchronous I/O Interface: io_uring
Linux 5.1 io_uring 加入
- 新的一系列 syscall, 用于创建 SQ, CQ, 提交 SQE array
- 这些结构 shared between Kernel and User via mmap
- Submission and completion work asynchronously
- Utilizes standard syscall backends for calls like readv(2), writev(2), or fsync(2); with same categories as previous
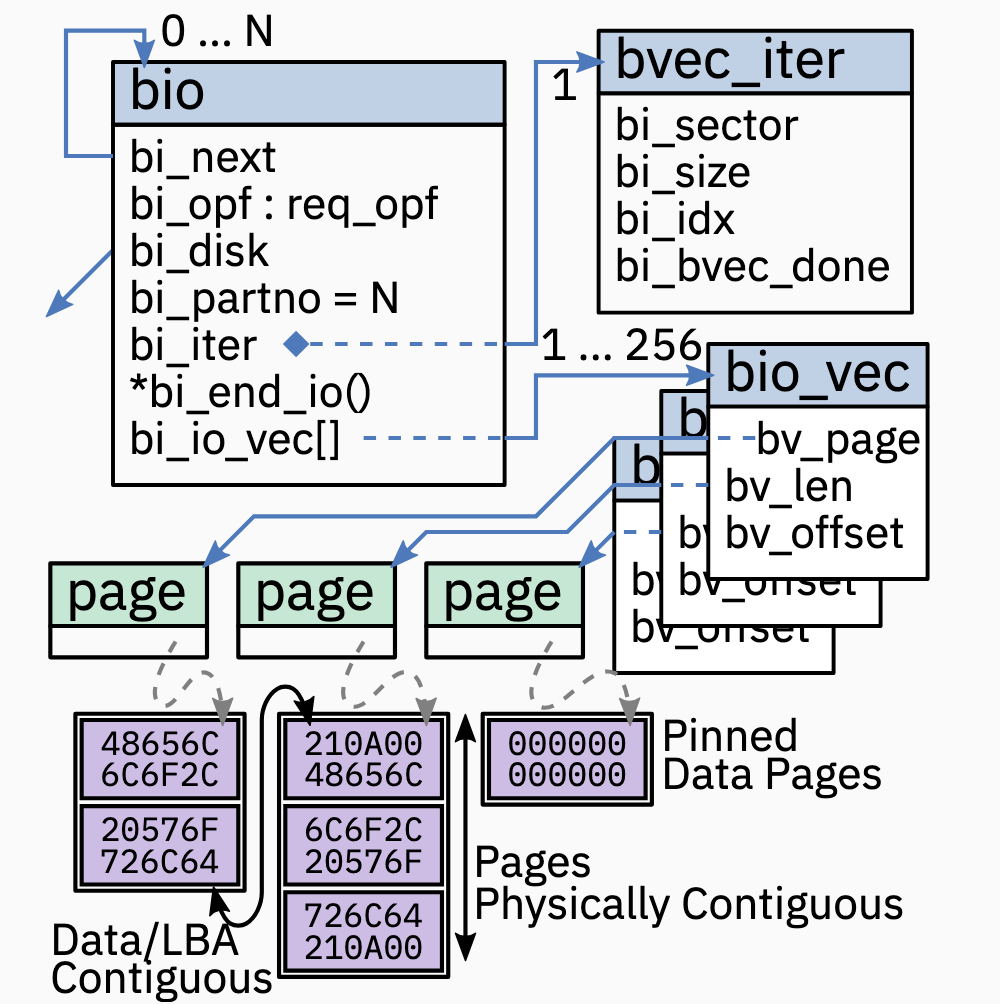
The I/O Unit of the Block Layer: BIO
- BIOs 表示一个正在进行的 I/O (in-flight I/O)
- Application data kept separate; array of
bio_vecs holds pointers to pages with application data (scatter/gather list) - Position and progress managed in
bvec_iter: bi_sectorstart sectorbi_sizesize in bytesbi_idxcurrent bvec indexbi_bvec_donefinished work in bytes- BIOs might be split when queue limits execeeded; or cloned when same data goes to different places(?????)
- 单个 BIO data 大小为 4GiB
Plugging and Merging
在将 bio 发送给 block device 先要将 bio 加入一个 “plugged” request queue, 以便发现一些可以 merge 的 request
Plugging:
- 当 VFS 生成 I/O requests 并且 submits 它们, 它会将 request 插入(plugs) target block device 的 request queue1
- 在 plug 里面的 request 不会直接被提交, 直到 unplugging
- Unplugging 的发生可能是显示地(explicitly), 或者是当 scheduled context switches
Merging:
- BIOs 和 requests 会和已经 queued / plugged requests 尝试 merge, 合并会两种类型
- Back-Merging: The new data fits to the end of an existing request
- Front-Merging: The new data fits to the beginning of an existing request
- Merging 通过 concatenating BIOs via
bi_next完成 - Merges 后的 request 必须遵守 queue limits
Entry Function into the Block Layer
以下是 submit_bio 的伪代码
- 如果是 I/O 是必要的(这里的意思是应该是不在 page cache 的情况), BIOs 会生成并且通过
submit_biosubmitted 到 block layer - 不一定保证是异步处理的; callback 通过
bio->bi_end_io(bio) - One submitted BIO can turn into several more(block queue limits, stacked device, …); each is also submitted via
submit_bio() - Especially for stacked devices this could exhaust kernel stack space -> turn recursion into iteration(approx.: dfs with stack)

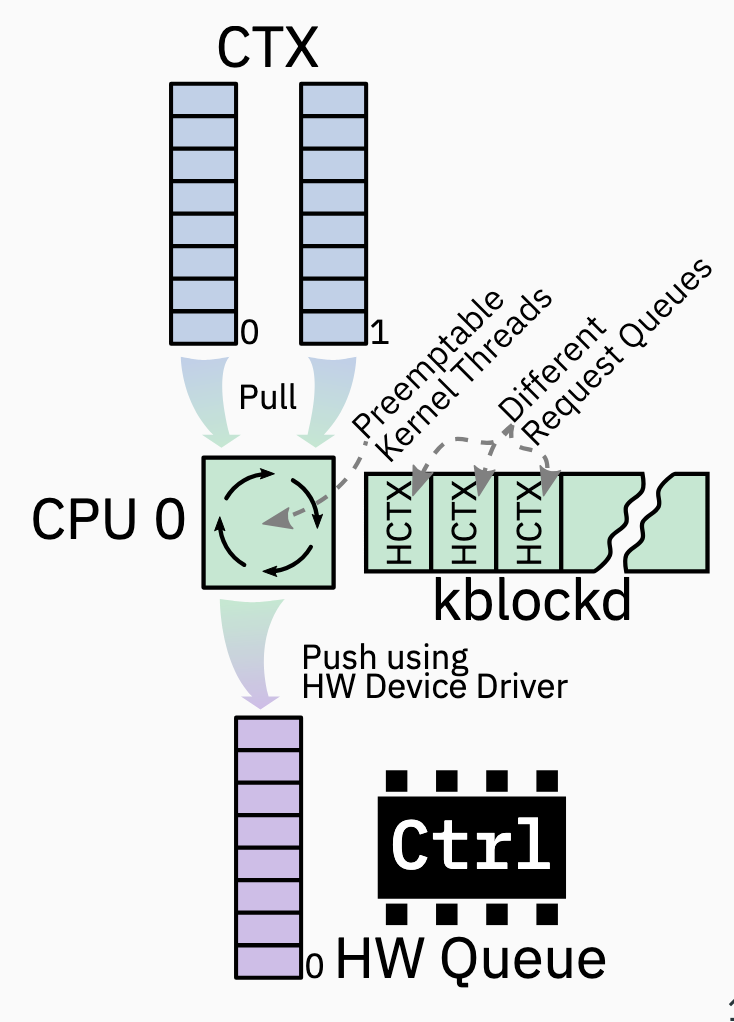
Request Submission and Dispatch
- 当一个 BIO 到达了 request queue, 会向对应的 HCTX 索要 tag
- 如果现在没有空闲的 tag, 则 back pressure
- The BIO is added to the associatec Request; via linking, this could be multiple BIOs per request
- Request 将会插入 software context FIFO queue, 或者是 Elevator(if enabled); the HCTX work-item is queued into
kblockd(即 “kernel block daemon”, kblockd is responsible for pulling these queued requests from the software context (or Elevator) and dispatching them to the hardware device driver) - 相关的 CPU 执行 HCTX work-item
- Work-item pulls queued requests out of associated software contexts or Elevators and hands them to HW device driver
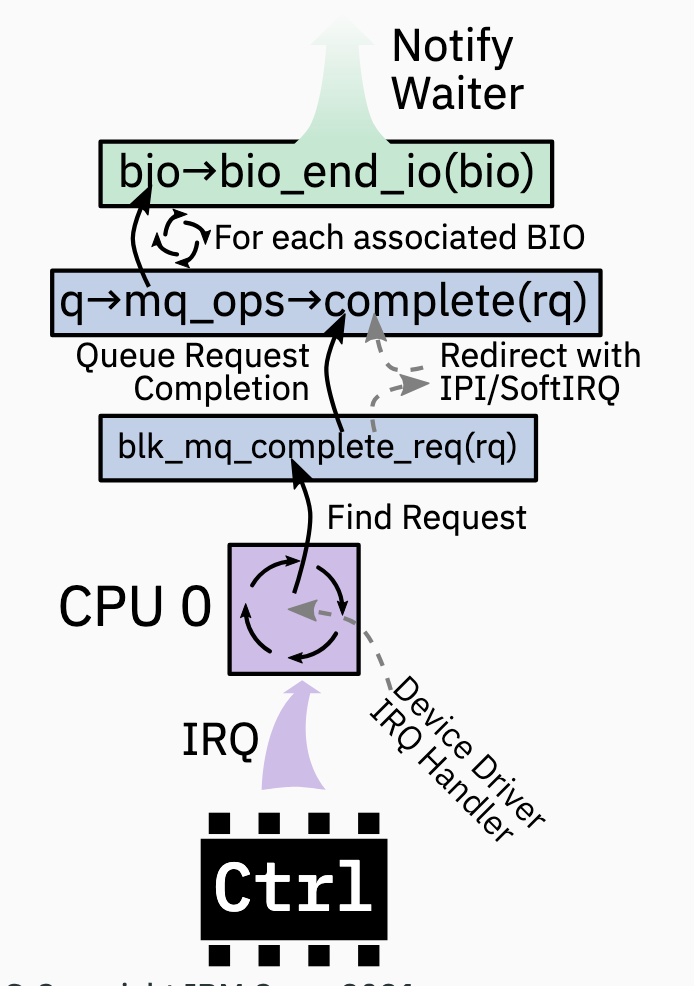
Request Completion
- 当 request 完成后, 一般通过中断来提醒
- To keep data CPU local, interrupts 应该绑定到与 MQ software context 相关的 CPU.(platform-/controller-/driver-dependant)
- 如果做不到, 则 blk-mq resorts to IPI(inter-processor interrupt) or SoftIRQ(software interrupt) otherwise
- The device driver is responsible for determining the corresponding block layer request for the signaled completion
- Progress is measurred by how many bytes were successfully completed; might cause re-schedule
- Process of completing a request is a bunch of callbacks to notify the waiting user-/kernel-thread
Block Layer Polling
- 中断是很慢的, 可能会有 context 的切换 => Similar to high speed networking, with high speed storage targets it can be beneficial to use Polling instead of Waiting for Interrupts to handle request completion
- Decreases response times and reduces overhead produced by interrupts on fast devices (尤其是速度很快的设备, 可以明显的减少 response time)
- Availlable in Linux since 4.10; only supportted by NVMe at this point (在当时)
- 开启方法
echo 1 > /sys/class/block/<name>/queue/io_poll - Enable for NVMe with module parameter: nvme.poll_queues=N
- Device driver creates separate HW queues taht have interrupts disabled
- 在当时, 只有 Direct I/O 支持
- Pass
RWF_HIPRItoreadv(2) /writev(2) - Pass
IORING_SETUP_IOPOLLtoio_uring_setup(2) for io_uring
- When used, application threads that issued I/O, or io_uring worker threads, actively poll in HW queues whether the issued request has been completed
Reference
Explicit block device plugging https://lwn.net/Articles/438256/ ↩︎